Tic-Tac-Toe Analysis using Clojure (Part 1)
Motivation
Tic-Tac-Toe (TTT), or Noughts and Crosses, is a simple children’s game. As a game, it is not particularly interesting – a few hours play reveals most of its secrets. It has also been widely analysed (see Wikipedia link above) so there is little new to be discovered. So why bother?
Well this is my first blog post and I thought it would be fitting to combine one of my earliest computing “wow” moments with one of my latest.
As a school kid I was fascinated by the idea of “codifying” TTT moves and responses as a set of tables (this was well before personal computers so it was all pencil and paper stuff). It seemed like magic to me that a “machine” could be made to play like a human and even beat them if they were not careful. Of course today, sophisticated programs can play complex games like chess, go, bridge, scrabble and even poker as well, or better, than expert human players.
My latest wow moment comes courtesy of the Clojure programming language. You could paraphase Spock’s often quoted misquote (apparently he never said it):
It’s Lisp, Jim, but not as we know it.
Clojure is a pragmatic, friendly and flexible functional language which comes with a laundry list of goodness including:
- power and simplicity of Lisp (the good parts :) with sane syntax
- beautiful data structures that are immutable!
- concurrency built-in from the ground up
- targets the JVM (and JavaScript through ClojureScript) to run fast on a large number of platforms
- has many excellent native libraries but also has tight integration with Java libraries. If Python comes with batteries, Clojure comes with a small substation!
Clojure is a relatively new language that is still evolving, some recent gains include go-like async channels and transducers. This newness does mean it lacks maturity in a few areas, and its Java ties and dynamic typing can also colour people’s views. But overall it is a terrific base that might finally realise the promise of Lisp that has largely languished for over 50 years.
Clojure is a simple language at its core, but it can be a challenge to grasp especially if you come from an imperative-style language background (C and Python in my case). Its functional nature and immutable data structures initially led me to a “wtf” moment where I wondered whether is was possible to write any non-trivial program in Clojure. Fortunately that moment was short lived, in part thanks to blogs that showed how Clojure code can be used in different problem scenarios.
Hopefully this blog might add to these, reveal TTT in a slightly different light, and encourage existing programmers to take a closer look at the power, elegance and joy of Clojure.
Disclosure
As the title of the blog suggests, I’m an enthusiast rather than an expert, so be warned.
Functional programming, by design, is “composable” — basically large pieces can be readily built from smaller ones. This is a powerful feature but often means there are several ways to achieve the same outcome. Contrast this with The Zen of Python’s:
There should be one – and preferably only one – obvious way to do it.
Each of these alternative ways usually comes with different degrees of clarity, conciseness, elegance, purity and compactness. Views will vary on which is best and this is frequently fairly subjective. There is no right answer here, so I’m happy to take advice from any interested readers, but for the code below, clarity is the main priority.
Basic Analysis
Tic-Tac-Toe (aka Noughts and Crosses) is a simple two-player game. Players take turns placing their token (usually an “X” for the first player and a “O” for the second player) on a 3×3 grid. The game continues until either a player gets three of their tokens in a “row” (vertically, horizontally or diagonally) in which case they win, or until there are no empty cells remaining, in which case the game is a draw.
All games can be no longer than nine moves with five X-moves and four O-moves, however games can be shorter if one or other player achieves a winning position in less than nine moves.
The game can be modelled as a game tree. The starting or root node is the blank board (or grid). This root node has nine child nodes representing the nine possible X-player moves. Each of these nodes has eight child nodes representing the eight possible O-player moves in response to the X-player move. The tree continues in this fashion until either a winning position is reached or the board is full without a winning position being achieved (ie. a draw).
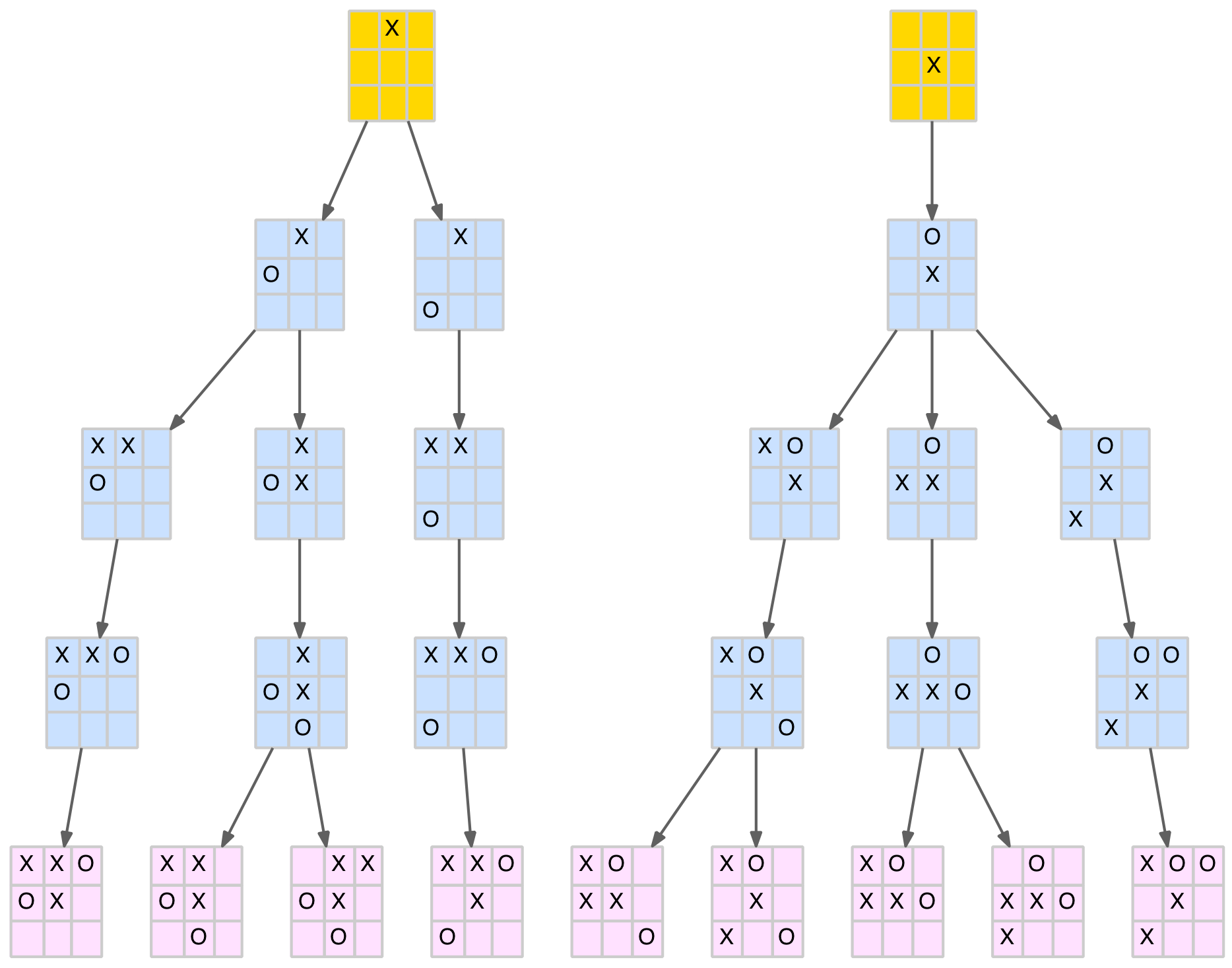
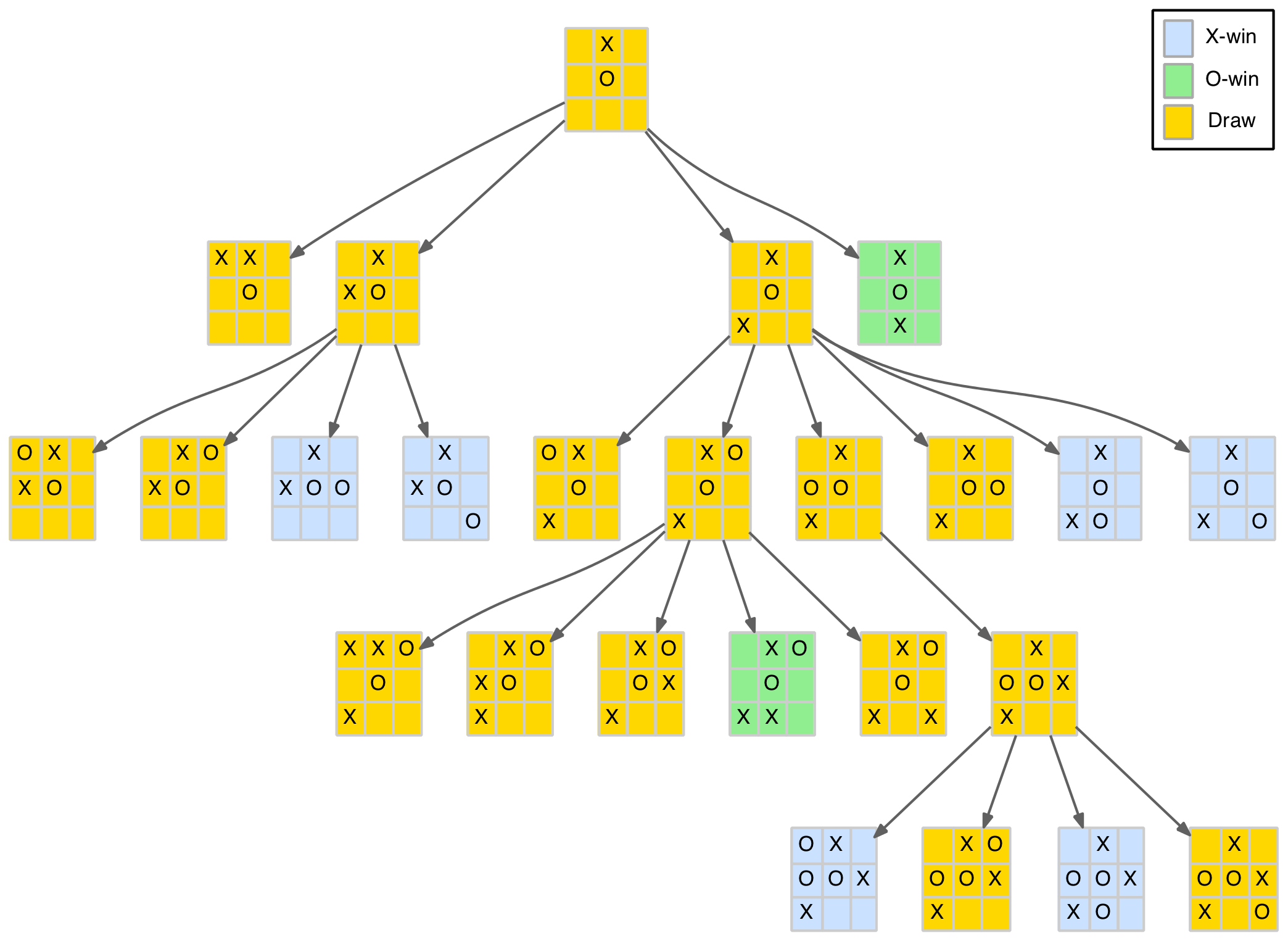
The game tree has 10 levels which will be labelled levels 0 to 9 (technically they should be labelled 1 to 10 but using 0 to 9 works well here as the level number equals the number of moves made at that level). Level 0 will be an empty board (root node) with no moves. Level 1 will be the nine child nodes that represent the first X-move and so on. The diagram below shows a partial game tree.
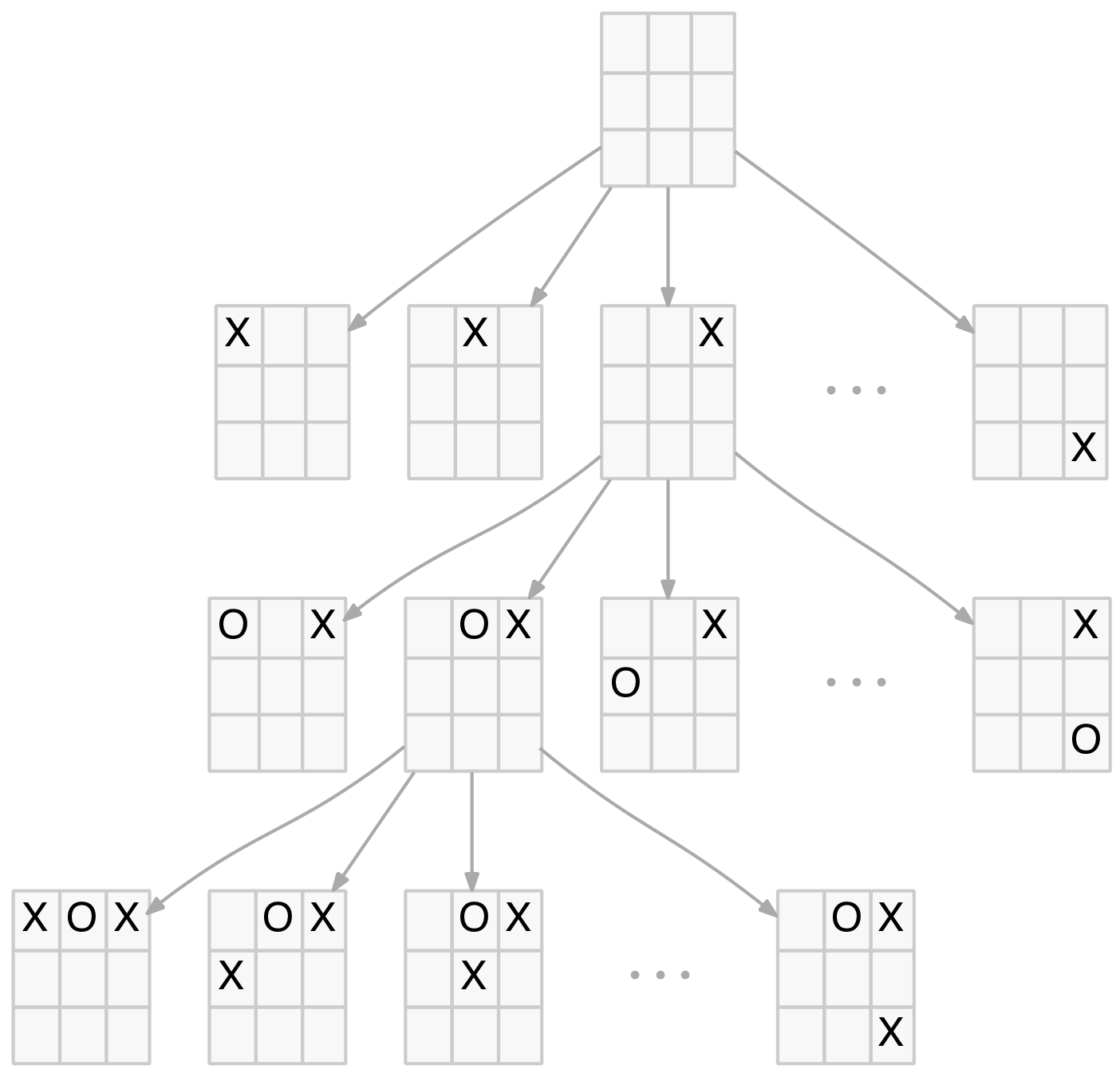
Partial TTT Game Tree
Upper Bounds
It is easy to calculate the maximum size of this tree if we ignore winning positions. This sets an upper bound to the tree size and helps scope the analysis task ahead. Later we will look ways to reduce the size of the tree by:
- stopping at winning positions
- identifying duplicate positions
- accounting for position symmetries
- considering “forced” moves
It is clear that level 0 has a single empty root node, level 1 has the nine first moves of the X-player. Level 2 will have eight O-player nodes for each of the nine nodes in level 1, or 9×8 nodes in total. Level 3 will have seven nodes for each of the level 2 nodes, or 9x8x7, and so forth until level 9 which will have 9x8x7x6x5x4x3x2x1 nodes. Those familiar with the factorial notation will recognise the level 9 result as 9!. It is easy to see the other levels are just factorial ratios (9!/9!, 9!/8!, 9!/7!, etc).
The following is a summary of the maximum size of the game tree:
Level Number Factorial Total
-------------------------------------------
0 1 9!/9! 1
1 9 9!/8! 9
2 9x8 9!/7! 72
3 9x8x7 9!/6! 504
4 9x8x7x6 9!/5! 3,024
5 9x8x7x6x5 9!/4! 15,120
6 9x8x7x6x5x4 9!/3! 60,480
7 9x8x7x6x5x4x3 9!/2! 181,440
8 9x8x7x6x5x4x3x2 9!/1! 362,880
9 9x8x7x6x5x4x3x2x1 9!/0! 362,880
--------------------------------------------
Total 986,410
From this we can see any analysis is computationally tractable because at worst there are less than 1 million nodes and the tree depth is a maximum of nine (so recursive analysis is not going to run into stack overflow problems).
Finally we can write some code to determine the tree size if we take into account winning positions. This will prune the tree at each winning node as it will become a leaf or terminal node. We would therefore expect the number of nodes to be reduced from the upper bound after level 5 which is the earliest case that three Xs can occur to make a winning position for the X-player.
Code Approach
To start, we need a representation of the TTT board. A Clojure vector is ideal as its elements can be accessed quickly using a cardinal index. Using a nine element vector to represent the nine cells on the board, its indexes (0-8) will be mapped to the board cells as follows:
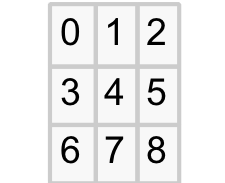
Each vector element, or board cell, will take one of three values represented by the Clojure keywords :x, :o and :e corresponding to an X-player token, an O-player token or an empty cell respectively.
An initially blank board would be represented as [:e :e :e :e :e :e :e :e :e]. As moves are played the :e values will be progressively replaced with :x and :o values.
Winning Positions
To account for winning positions we can simply walk the game tree and test each node for one of two terminal conditions:
- Won position for the last player to move
- No more empty cells (ie. a draw)
The first thing we need is a couple of helper functions to generate the available moves for a given board and to check for won positions.
(defn gen-moves
"Return a list of all valid moves on the specified board or nil"
[board]
(filter #(= :e (board %)) (range 9)))
(defn win-board?
"Determine if a board is a win for a given player."
[board player]
(let [win-seqs (list [0 1 2] [3 4 5] [6 7 8] ; Horizontal
[0 3 6] [1 4 7] [2 5 8] ; Vertical
[0 4 8] [2 4 6]) ; Diagonal
win (fn [win-seq] (every? #(= player (board %)) win-seq))]
(some win win-seqs)))
These functions are fairly straightforward. The first function just returns a sequence of indexes for each empty cell (those containing :e) found on the board or nil if there are none.
The second works its way through a (constant) list of vectors that denote the three indexes that represent the eight (3 x horizontal, 3 x vertical and 2 x diagonal) winning sequences, and checks to see if any hold all three of the given player’s token (:x or :o). If you are new to Clojure you should note that the let form allows you to bind not just values but also functions, and that the win function includes external values within the main function’s scope (‘board’ and ‘player’) in addition to its own ‘win-seq’ argument.
For the initial analysis, the number and type of nodes at each level of the game tree will be determined. To do this the following data structure will be used. It is a map of maps. Each level number is a key of the first map, with its values being a second map of attribute/value pairs. The attributes will be node types and the values will be node counts.
{0 {:attr1 val1, :attr2 val2, ...}
1 {:attr1 val1, :attr2 val2, ...}
.
.
9 {:attr1 val1, :attr2 val2, ...}}
Returned data structure format
We can now write the main game tree walking function. This is a recursive depth-first function that examines each node and determines whether it is a terminal or internal node. If it is a terminal node (ie. a win or draw) it just returns some details about the node (ie. type and depth). If it is an internal node, it must recursively calls each child node passing updated arguments such as a new board incorporating the specific move for that child. Importantly it must also aggregate the return values for each child, including its own value, and pass them back to its calling parent.
It is also worth noting that we are not walking an existing game tree but rather temporarily constructing it as we go. Indeed only the current node and its immediate ancestors exist at any time (held in the call stack).
(defn ttt-walk
"Recursively walk the TTT game tree and aggregate results for each node"
[board last-player next-player level win-board? gen-moves]
(if (win-board? board last-player)
{level {last-player 1}} ; Terminal win node
(let [moves (gen-moves board)]
(if (empty? moves)
{level {:draw 1}} ; Terminal draw node
(reduce (fn [a b] (merge-with #(merge-with + %1 %2) a b))
{level {:inode 1}} ; Internal node (inode)
(for [m moves]
(ttt-walk (assoc board m next-player)
next-player
last-player
(inc level)
win-board?
gen-moves)))))))
(ttt-walk [:e :e :e :e :e :e :e :e :e] :o :x 0 win-board? gen-moves)
;=> (after some reordering for clarity)
{0 {:inode 1},
1 {:inode 9},
2 {:inode 72},
3 {:inode 504},
4 {:inode 3024},
5 {:inode 13680, :x 1440},
6 {:inode 49392, :o 5328},
7 {:inode 100224, :x 47952},
8 {:inode 127872, :o 72576},
9 {:draw 46080, :x 81792}}
The walk function takes the board, the last and next player (clearly only one is required as the other can be deduced but it is simple and clear to use both), the level and the two helper functions it uses (see below). It first checks to see if the board was won by the last player. If so, it returns a fragment of the data structure above with the level, node type and count. Otherwise it gets the available moves and again returns if there are none (ie. a draw) with a similar data structure. Finally, if there are moves, it recursively calls itself for each available move with updated arguments and aggregates the returned results with the reduce function. The reduce function’s reducing function does the heavy lifting combining the data structure fragments returned into one aggregated structure using merge-with (twice) to add together counts from like node types. The initial value of the reduce function is used to include the parent node details.
The code above attempts to be as pure as possible from a functional perspective. In particular, all its inputs are passed as arguments, including functions it calls, rather than using global references, and the returned results are aggregated and passed back up the calling chain. While this approach might be functionally pure it is not particularly pragmatic in this situation. The aggregation of child results is somewhat cumbersome which detracts from the overall intent.
A more straightforward, if less pure, approach is to just update the data structure directly as each node is processed. Clojure was designed with real world state management in mind and it provides several ways to do this safely.
By using a Clojure atom to hold the data structure we can recast the walk function to directly update it using the swap! function. This approach will be continued as the code is enhanced to include further game tree pruning measures. The code is essentially the same only a ‘results’ argument has been added which is a reference to the data structure and, for clarity, the two helper functions are no longer passed as arguments.
One final refinement is the use of a pre-constructed data structure using sorted-maps instead of the default hash-maps. This is purely an aesthetic measure that means the results display in order on my IDE. It would, of course, also be easy to write an output function to display/print the results in any particular order or format. Both the ‘unordered’ and ‘order’ calls are shown below for completeness. The ordered one will be used for all future calls.
(defn ttt-walk
"Recursively walk the TTT game tree and update results for each node"
[board last-player next-player level results]
(if (win-board? board last-player)
(swap! results update-in [level last-player] (fnil inc 0)) ; Win node
(let [moves (gen-moves board)]
(if (empty? moves)
(swap! results update-in [level :draw] (fnil inc 0)) ; Draw node
(do
(swap! results update-in [level :inode] (fnil inc 0)) ; Internal node
(doseq [m moves]
(ttt-walk (assoc board m next-player)
next-player
last-player
(inc level)
results)))))))
(let [results (atom {})]
(ttt-walk [:e :e :e :e :e :e :e :e :e] :o :x 0 results)
@results)
;
; By setting up an empty result structure using 'sorted-maps' instead
; of the default (unsorted) 'hash-map' the output is correctly ordered.
;
(let [resmap (into (sorted-map) (for [n (range 10)] [n (sorted-map)]))
results (atom resmap)]
(ttt-walk [:e :e :e :e :e :e :e :e :e] :o :x 0 results)
@results)
;=>
{0 {:inode 1},
1 {:inode 9},
2 {:inode 72},
3 {:inode 504},
4 {:inode 3024},
5 {:inode 13680, :x 1440},
6 {:inode 49392, :o 5328},
7 {:inode 100224, :x 47952},
8 {:inode 127872, :o 72576},
9 {:draw 46080, :x 81792}}
Gratifyingly the results from both versions of the walk function are identical and are in line with what would be expected from the initial upper bound calculations. For the first four levels, where no winning positions can occur the node counts exactly match the calculated ones. At the fifth level, we see the first X-player winning position counts but note the sum of these and the internal nodes still equals the calculated count as expected. From there on, the actual node counts reduce compared to the calculated ones as the winning nodes no longer have children. Also, as expected, the X-player wins occur on the odd levels, while the O-player wins occur on the even levels.
The table below summarises these results. This table will be used to track our progress as we implement later pruning measures. Note a drawn node (marked :draw in the code results) is the same as a level 9 internal node (:inode). So for brevity, in the table, drawn nodes are shown on the ‘Internal’ node line at level 9 rather than on a separate line of their own.
| Node Level |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
Total |
| Upper Bound |
1 |
9 |
72 |
504 |
3,024 |
15,120 |
60,480 |
181,440 |
362,880 |
362,880 |
986,410 |
| Actual after accounting for winning nodes |
| Internal |
1 |
9 |
72 |
504 |
3,024 |
13,680 |
49,392 |
100,224 |
127,872 |
46,080 |
340,858 |
| X-wins |
|
|
|
|
|
1,440 |
|
47,952 |
|
81,792 |
131,184 |
| O-wins |
|
|
|
|
|
|
5,328 |
|
72,576 |
|
77,904 |
| Total |
1 |
9 |
72 |
504 |
3,024 |
15,120 |
54,720 |
148,176 |
200,448 |
127,872 |
549,946 |
As the table shows, by taking account of winning positions the size of the game tree is reduced by almost a half. Are there other ways we can prune the tree?
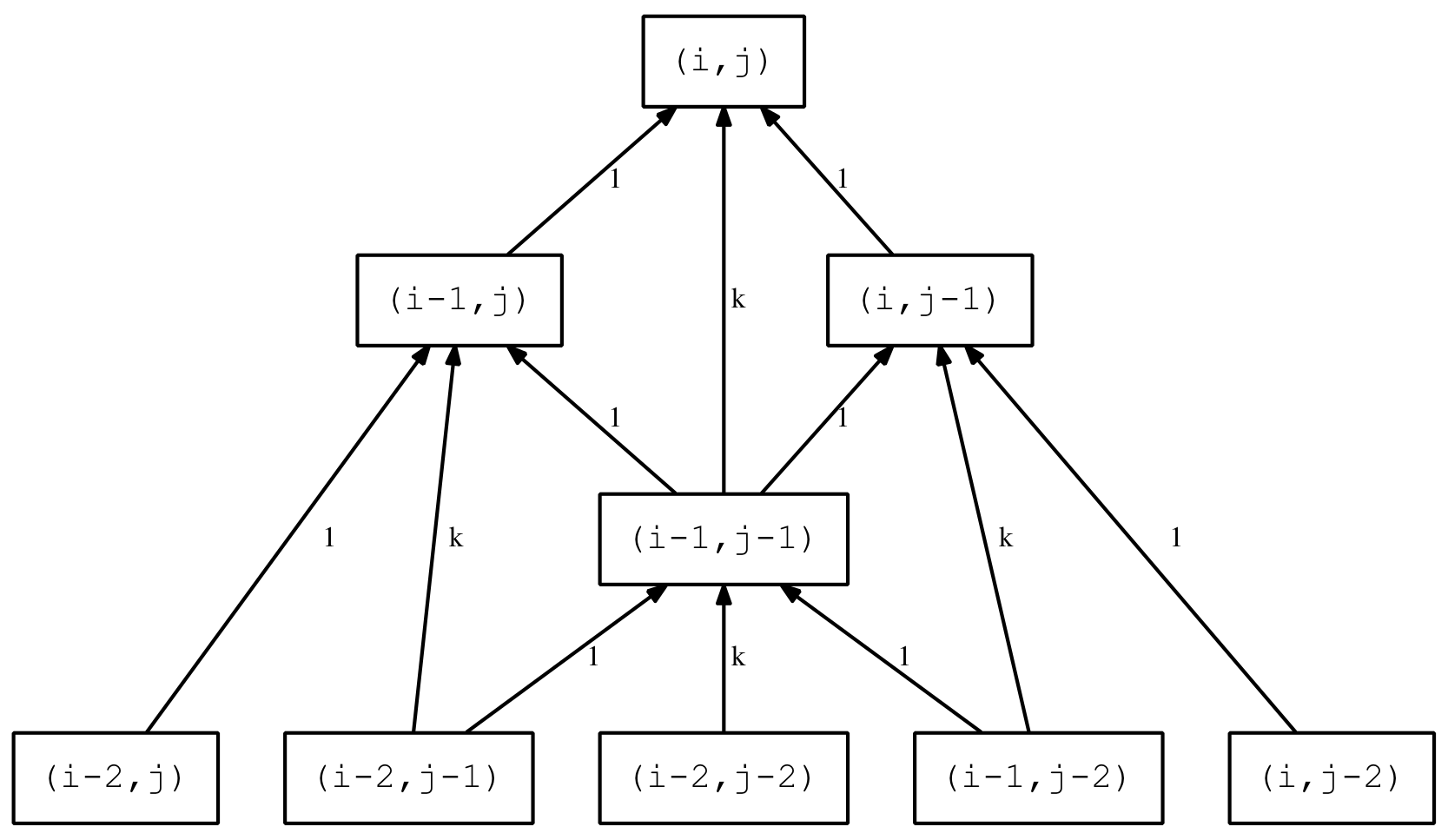
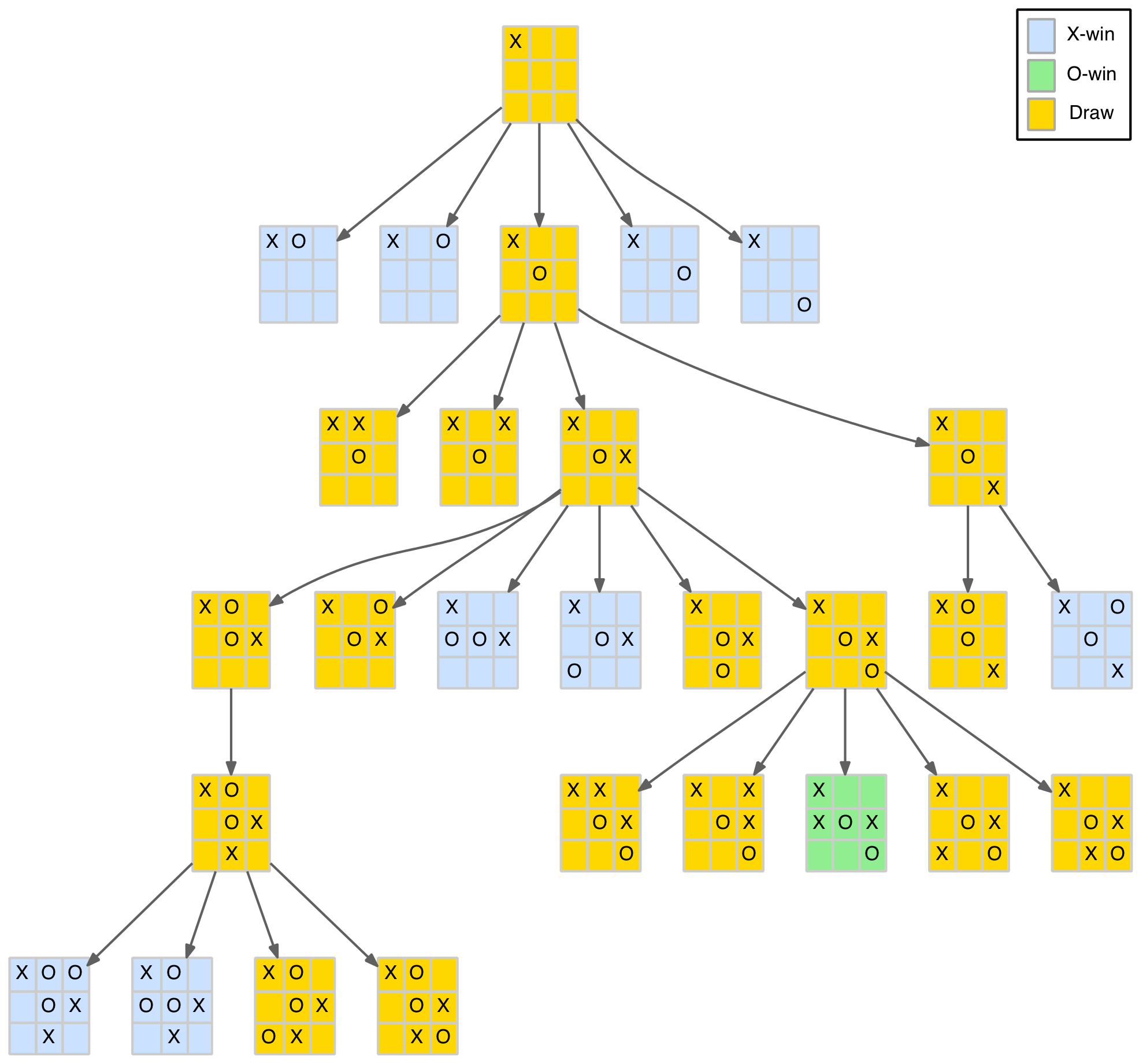
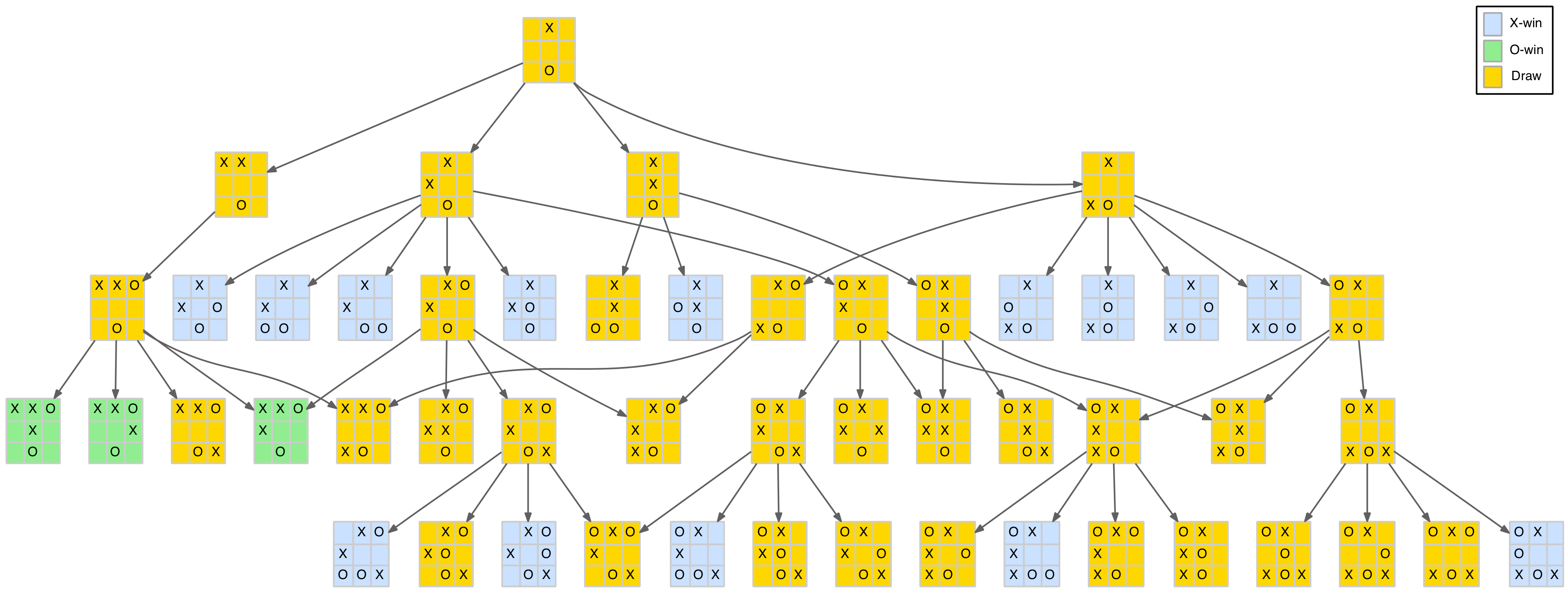
Duplicated Positions
A little thought leads to the realisation that the same position can be reached by different combinations of the same moves. This means identical positions will occur in different branches of the tree. A simple example is shown below.
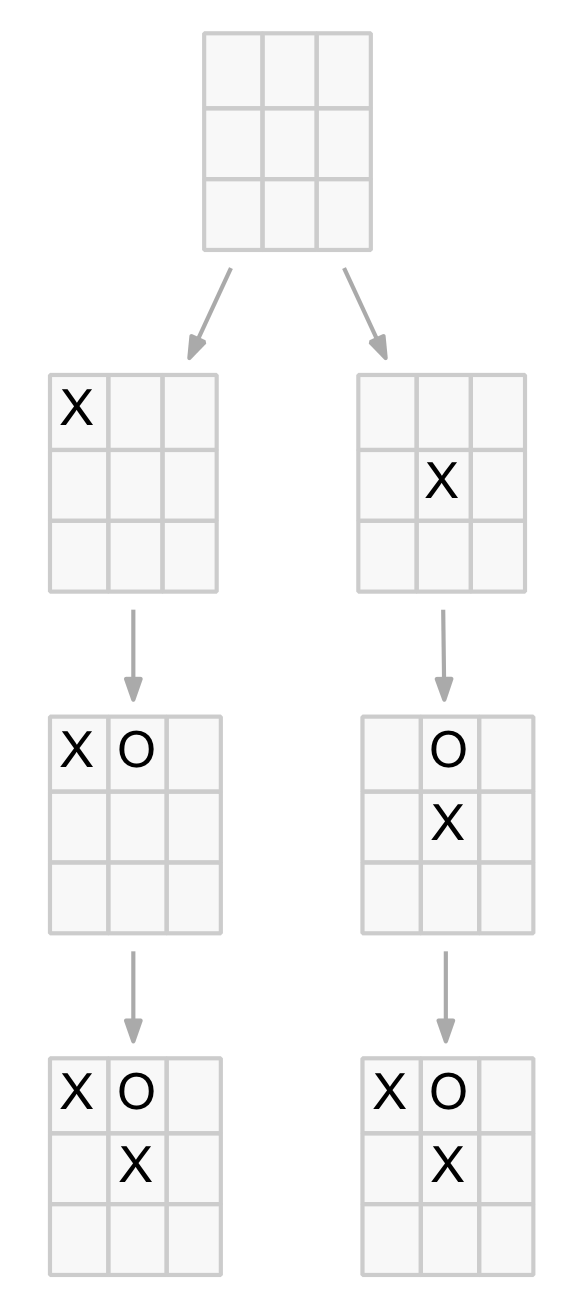
Duplicated node example
Not only are these positions duplicated but all their descendants are also duplicated in later levels. The degree of duplication can be calculated based on the number of moves made by each player. For example, in a position with three Xs and two Os, the first X could be played in any of three places, the second X in any of the two remaining places and the third in the one remaining place which is 3x2x1 or 3! ways. Similarly the first O can be in either of two positions and then in the one remaining position which is 2×1 or 2! ways. So in total there are 3!2! = 12 ways that position could have been reached. In general, if a position has n Xs and m Os then there are n!m! duplicates of that position. If we recalculate the upper bound discounting for duplicate nodes we get a significant reduction in the game tree size as shown in the updated table below:
Duplication De-duplicated
Level Number Factorial Total Factor Total
-----------------------------------------------------------------------
0 1 9!/9! 1 0!x0!=1 1
1 9 9!/8! 9 1!x0!=1 9
2 9x8 9!/7! 72 1!x1!=1 72
3 9x8x7 9!/6! 504 2!x1!=2 252
4 9x8x7x6 9!/5! 3,024 2!x2!=4 756
5 9x8x7x6x5 9!/4! 15,120 3!x2!=12 1260
6 9x8x7x6x5x4 9!/3! 60,480 3!x3!=36 1680
7 9x8x7x6x5x4x3 9!/2! 181,440 4!x3!=144 1260
8 9x8x7x6x5x4x3x2 9!/1! 362,880 4!x4!=576 630
9 9x8x7x6x5x4x3x2x1 9!/0! 362,880 5!x4!=2880 126
-----------------------------------------------------------------------
Total 986,410 6046
The ‘De-duplicated Total’ column is just the original ‘Total’ column divided by the ‘Duplication Factor’.
The tree walking code above can be readily modified to check for duplicates by maintaining a set of board positions as the tree is walked and checking each new node for membership of that set. The modified code below has the main changes highlighted. Note a new argument ‘dups’ is introduced to hold known boards (ie. those already visited).
(defn ttt-walk
"Recursively walk the TTT game tree and update results for each node"
[board last-player next-player level dups results]
(if (contains? @dups board)
(swap! results update-in [level :dup] (fnil inc 0)) ; Duplicate node
(do
(swap! dups conj board)
(if (win-board? board last-player)
(swap! results update-in [level last-player] (fnil inc 0)) ; Win node
(let [moves (gen-moves board)]
(if (empty? moves)
(swap! results update-in [level :draw] (fnil inc 0)) ; Draw node
(do
(swap! results update-in [level :inode] (fnil inc 0)) ; Internal node
(doseq [m moves]
(ttt-walk (assoc board m next-player)
next-player
last-player
(inc level)
dups
results)))))))))
(let [resmap (into (sorted-map) (for [n (range 10)] [n (sorted-map)]))
results (atom resmap)
dups (atom #{})]
(ttt-walk [:e :e :e :e :e :e :e :e :e] :o :x 0 dups results)
@results)
;=>
{0 {:inode 1},
1 {:inode 9},
2 {:inode 72},
3 {:dup 252, :inode 252},
4 {:dup 756, :inode 756},
5 {:dup 2520, :inode 1140, :x 120},
6 {:dup 3040, :inode 1372, :o 148},
7 {:dup 2976, :inode 696, :x 444},
8 {:dup 1002, :inode 222, :o 168},
9 {:draw 16, :dup 144, :x 62}}
As shown by the updated tracking table below, these results align well with the new de-duplicated upper bound. They match perfectly up to level 5 when winning nodes start to prune the tree and the node counts drop away as in the earlier example. The large reduction in the size of the tree is also encouraging as it hints at the underlying simplicity of the game.
| Node Level |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
Total |
| Upper Bound |
1 |
9 |
72 |
504 |
3,024 |
15,120 |
60,480 |
181,440 |
362,880 |
362,880 |
986,410 |
| Actual after accounting for winning nodes |
| Internal |
1 |
9 |
72 |
504 |
3,024 |
13,680 |
49,392 |
100,224 |
127,872 |
46,080 |
340,858 |
| X-wins |
|
|
|
|
|
1,440 |
|
47,952 |
|
81,792 |
131,184 |
| O-wins |
|
|
|
|
|
|
5,328 |
|
72,576 |
|
77,904 |
| Total |
1 |
9 |
72 |
504 |
3,024 |
15,120 |
54,720 |
148,176 |
200,448 |
127,872 |
549,946 |
| After accounting for duplicate nodes |
| Upper Bound |
1 |
9 |
72 |
252 |
756 |
1,260 |
1,680 |
1,260 |
630 |
126 |
6,046 |
| Actual after accounting for duplicate and winning nodes |
| Internal |
1 |
9 |
72 |
252 |
756 |
1,140 |
1,372 |
696 |
222 |
16 |
4,536 |
| X-wins |
|
|
|
|
|
120 |
|
444 |
|
62 |
626 |
| O-wins |
|
|
|
|
|
|
148 |
|
168 |
|
316 |
| Total |
1 |
9 |
72 |
252 |
756 |
1,260 |
1,520 |
1,140 |
390 |
78 |
5,478 |
Symmetric Positions
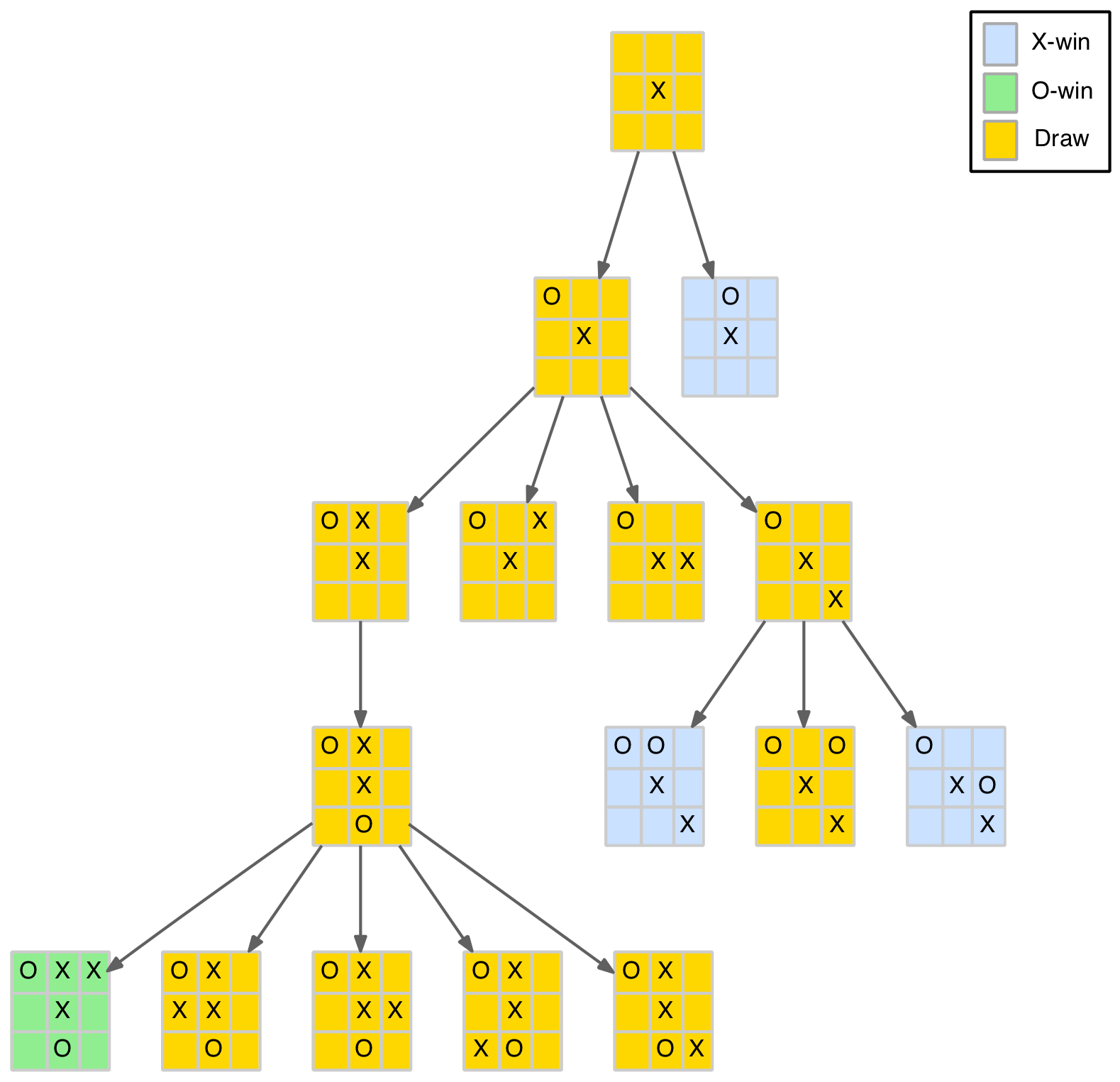
The next stage in tree pruning is to account for position symmetries. It is fairly obvious that although there are nine first X-player moves, only three are distinct (a corner, an edge or the centre). The rest are just rotations or reflections of these three. The same holds for the O-player responses to these three moves. There are only five, five and two, respectively, distinct responses as shown in the diagram below.
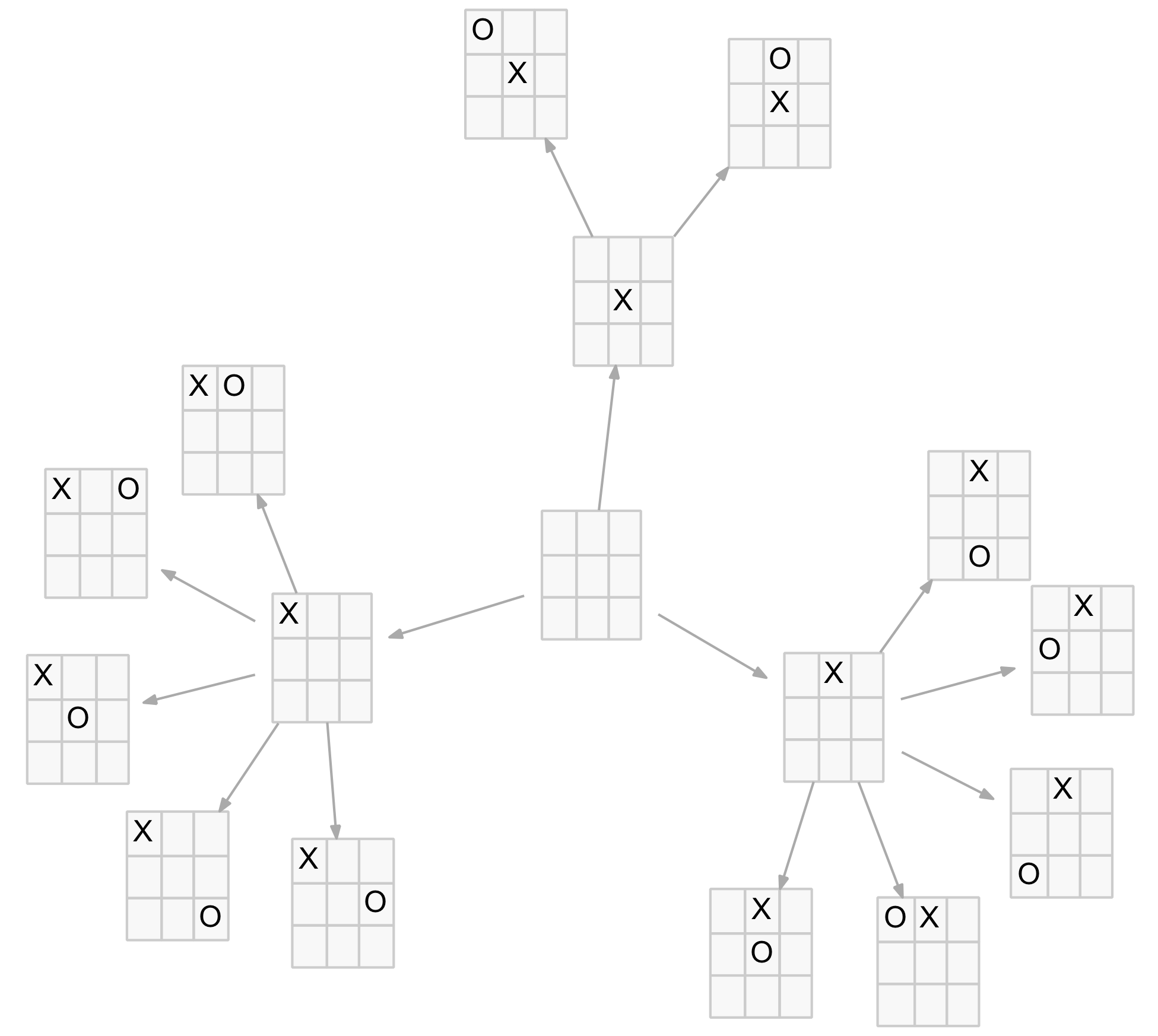
Distinct positions after two moves
This means instead of the original 9×8=72 nodes at level 2 in the game tree there are actually only 12 distinct nodes. Similar symmetries exist at other levels. A little experimentation (or theory for those with linear transformation skills) shows there are seven symmetries involved: 3 rotations (90, 180 and 270 degrees) and 4 reflections (horizontally, vertically and along the two diagonals).
For some positions, not all of these symmetries yield unique new positions (ie. after a transformation the new position is either identical to the original or to one of the other transformations). But many positions do result in seven unique new positions, one example is shown below.
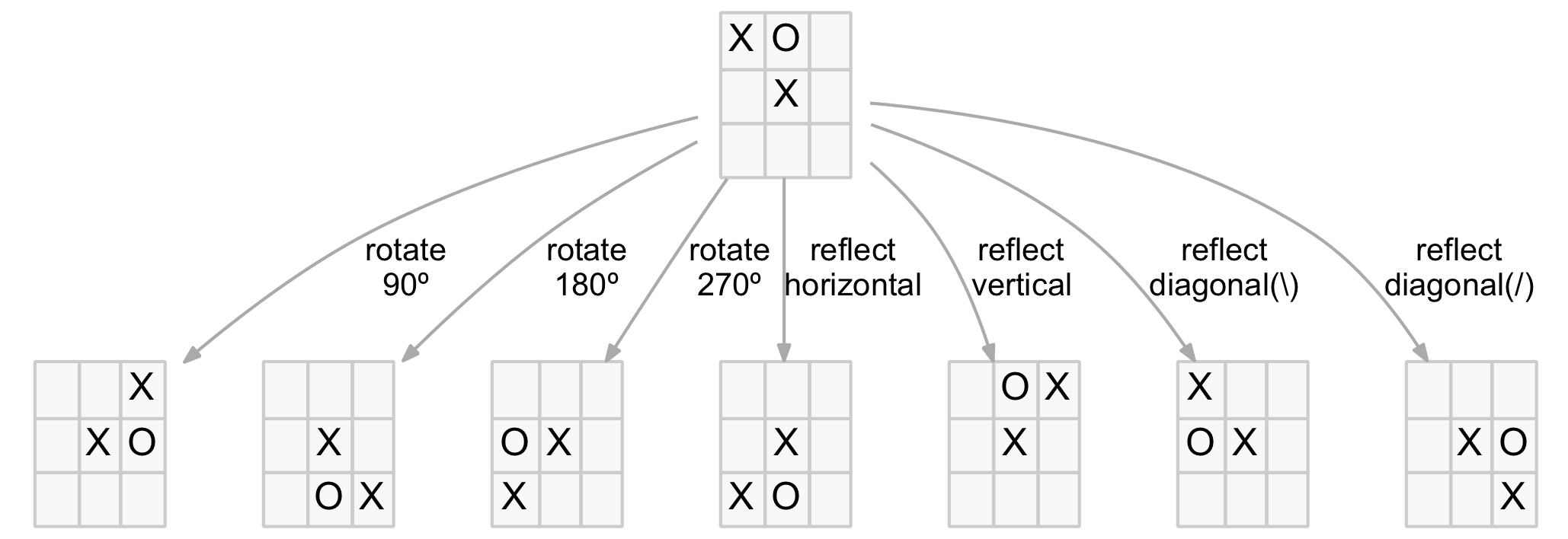
Seven symmetric transformations
To account for symmetries, a new helper function is required that will return a set of boards that are symmetries of the specified board. These boards can then be bypassed in the same way as duplicates. Note that duplicates and symmetries are orthogonal (ie. they don’t overlap) so there is no interference between them that might affect node counts or the order in which they are tested/excluded.
(defn board-symmetries
"Return a set of all symmetric boards based on rotations and
reflections of the specified board."
[board]
(let [transforms
[[6 3 0 7 4 1 8 5 2] ; Rotation of 90 degrees
[8 7 6 5 4 3 2 1 0] ; Rotation of 180 degrees
[2 5 8 1 4 7 0 3 6] ; Rotation of 270 degrees
[6 7 8 3 4 5 0 1 2] ; Horizontal reflection about 3 4 5
[2 1 0 5 4 3 8 7 6] ; Vertical reflection about 1 4 7
[0 3 6 1 4 7 2 5 8] ; Diagonal reflection about 0 4 8
[8 5 2 7 4 1 6 3 0]]] ; Diagonal reflection about 2 4 6
(disj (set (for [t transforms] (vec (map board t)))) board)))
The function above uses vectors to hold index mappings of each transformation (rotations and reflections) which it applies to the specified board to produce seven new boards. These are combined into a set which will eliminate any identical boards and disj is used to remove the original board if it happened to be generated by one of the transformations.
With duplicates we just added (conj) each new board as it was processed for later checking. For symmetries we need to add all the symmetric boards that arise so we use the union function to maintain a set of all boards that are known to be symmetries of processed nodes.
The previous tree walking code has been modified to track and bypass symmetric nodes. The main changes are highlighted. Note a new argument ‘syms’ is introduced to hold symmetric boards.
(defn ttt-walk
"Recursively walk the TTT game tree and update results for each node"
[board last-player next-player level dups syms results]
(cond
(contains? @dups board)
(swap! results update-in [level :dup] (fnil inc 0)) ; Duplicate node
(contains? @syms board)
(swap! results update-in [level :sym] (fnil inc 0)) ; Symmetric node
:else
(do
(swap! dups conj board)
(swap! syms clojure.set/union (board-symmetries board))
(if (win-board? board last-player)
(swap! results update-in [level last-player] (fnil inc 0)) ; Win node
(let [moves (gen-moves board)]
(if (empty? moves)
(swap! results update-in [level :draw] (fnil inc 0)) ; Draw node
(do
(swap! results update-in [level :inode] (fnil inc 0)) ; Internal node
(doseq [m moves]
(ttt-walk (assoc board m next-player)
next-player
last-player
(inc level)
dups
syms
results)))))))))
(let [resmap (into (sorted-map) (for [n (range 10)] [n (sorted-map)]))
results (atom resmap)
dups (atom #{})
syms (atom #{})]
(ttt-walk [:e :e :e :e :e :e :e :e :e] :o :x 0 dups syms results)
@results)
;=>
{0 {:inode 1},
1 {:inode 3, :sym 6},
2 {:inode 12, :sym 12},
3 {:dup 3, :inode 38, :sym 43},
4 {:dup 44, :inode 108, :sym 76},
5 {:dup 161, :inode 153, :sym 205, :x 21},
6 {:dup 225, :inode 183, :o 21, :sym 183},
7 {:dup 220, :inode 95, :sym 176, :x 58},
8 {:dup 82, :inode 34, :o 23, :sym 51},
9 {:draw 3, :dup 11, :sym 8, :x 12}}
Again these results look consistent with our expectations. The counts for level 1 and 2 agree with the 3 and 12 node counts identified in the diagram above, and the overall node counts have shrunk again at all levels.
As shown by the following updated tracking table we are now down to a game tree of just 765 nodes, a big reduction from the half million plus we started with.
| Node Level |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
Total |
| Upper Bound |
1 |
9 |
72 |
504 |
3,024 |
15,120 |
60,480 |
181,440 |
362,880 |
362,880 |
986,410 |
| Actual after accounting for winning nodes |
| Internal |
1 |
9 |
72 |
504 |
3,024 |
13,680 |
49,392 |
100,224 |
127,872 |
46,080 |
340,858 |
| X-wins |
|
|
|
|
|
1,440 |
|
47,952 |
|
81,792 |
131,184 |
| O-wins |
|
|
|
|
|
|
5,328 |
|
72,576 |
|
77,904 |
| Total |
1 |
9 |
72 |
504 |
3,024 |
15,120 |
54,720 |
148,176 |
200,448 |
127,872 |
549,946 |
| After accounting for duplicate nodes |
| Upper Bound |
1 |
9 |
72 |
252 |
756 |
1,260 |
1,680 |
1,260 |
630 |
126 |
6,046 |
| Actual after accounting for duplicate and winning nodes |
| Internal |
1 |
9 |
72 |
252 |
756 |
1,140 |
1,372 |
696 |
222 |
16 |
4,536 |
| X-wins |
|
|
|
|
|
120 |
|
444 |
|
62 |
626 |
| O-wins |
|
|
|
|
|
|
148 |
|
168 |
|
316 |
| Total |
1 |
9 |
72 |
252 |
756 |
1,260 |
1,520 |
1,140 |
390 |
78 |
5,478 |
| Actual after accounting for symmetric, duplicate and winning nodes |
| Internal |
1 |
3 |
12 |
38 |
108 |
153 |
183 |
95 |
34 |
3 |
630 |
| X-wins |
|
|
|
|
|
21 |
|
58 |
|
12 |
91 |
| O-wins |
|
|
|
|
|
|
21 |
|
23 |
|
44 |
| Total |
1 |
3 |
12 |
38 |
108 |
174 |
204 |
153 |
57 |
15 |
765 |
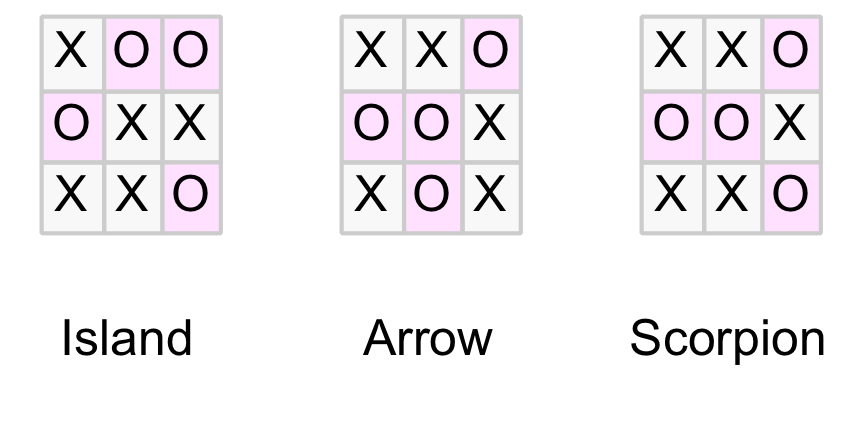
One interesting result is that there are only three distinct drawn boards (shown below). As they can occur in different orientations it is easier to recognise them as patterns. The Os are highlighted below to emphasis the shape and some euphemistic names are attached (although the reader may have better suggestions).
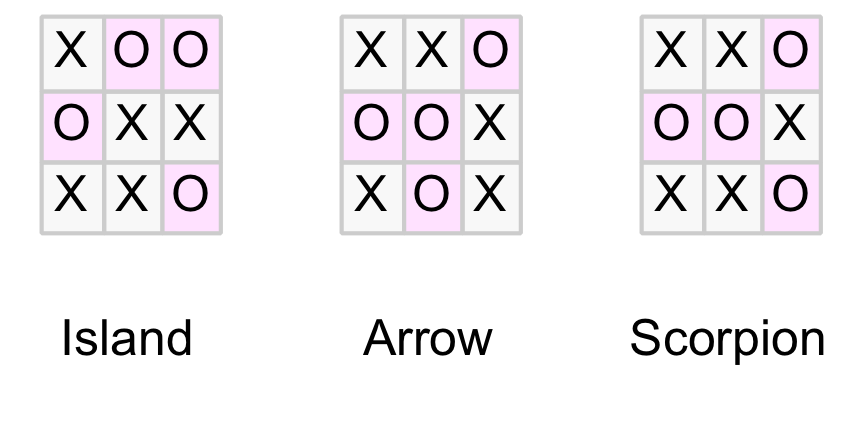
The three patterns for all drawn boards
Looking at it another way, for a position to be a draw, the four O-tokens must cover all the winning sequences and must not form a winning sequence themselves. So at least one O-token must be in each row, column and diagonal. This significantly limits the number of combinations. The code below does a quick check of all the ways four tokens can be placed on a board so that they cover each of the eight winning sequences but don’t create a winning sequence themselves. (Please note this code is optimised for clarity, not performance, as it is a one-off but it still runs in under 0.5 seconds on my laptop.)
(def win-seqs [[0 1 2] [3 4 5] [6 7 8] ; Horizontal wins
[0 3 6] [1 4 7] [2 5 8] ; Vertical wins
[0 4 8] [2 4 6]]) ; Diagonal wins
(for [a (range 9) b (range 9) c (range 9) d (range 9)
:let [x (set [a b c d])]
:when (and
(< a b c d)
(every? #(some x %) win-seqs)
(every? #(not-every? x %) win-seqs))]
[a b c d])
;=>
([0 1 5 6] [0 2 3 7] [0 2 4 7] [0 2 5 7]
[0 4 5 6] [0 4 5 7] [0 5 6 7] [1 2 3 8]
[1 3 4 8] [1 3 6 8] [1 4 5 6] [1 4 6 8]
[1 5 6 8] [2 3 4 7] [2 3 4 8] [2 3 7 8])
The reader can confirm that the resulting 16 indexes represent 4 x Arrow, 4 x Scorpion, and 8 x Island patterns as would be expected when symmetries are taken into account (note the tracking table shows 16 drawn boards before symmetries were excluded).
It is a testament to the power of Clojure (and similar modern languages) that this check can be programmed in a few lines of code (technically two). Not only is the code concise, it is also ‘safe’ in the sense that edge-cases, boundary conditions, etc. are all abstracted away.
Forcing Moves
One final refinement which leads into the second part of this blog – covering player strategy – is that most players are able to spot a winning sequence if it is available and also a blocking move should the opponent be about to win (ie. has two-in-a-row). We can further prune the tree by assuming a player will always:
- make a winning move if one is available (and forgo all other moves)
- make a blocking move if the opponent threatens to win on the next move (ie. the opponent has two-in-a-row)
A straightforward way to achieve this is to modify the move generating function to check the above conditions, and if found, to return only a single move (ie. either the winning or blocking move). If the conditions don’t apply then return the list of all valid moves as before.
The modified function (now called gen-moves-forced) is shown below. Note ‘next-player’ and ‘last-player’ variables have been abbreviated to ‘next-p’ and ‘last-p’ so the code fits better on the limited blog real estate – not a practice I would normally encourage :).
(defn gen-moves-forced
"Return a restricted list of moves based on these priorities:
1. Make a winning move if one exists
2. Block the opponent from winning
3. Otherwise - make any move (ie. return all valid moves)"
[board last-p next-p]
(let [moves (filter #(= :e (board %)) (range 9))
wins (filter #(win-board? (assoc board % next-p) next-p) moves)
blocks (filter #(win-board? (assoc board % last-p) last-p) moves)]
(cond
(not-empty wins) (list (first wins))
(not-empty blocks) (list (first blocks))
:else moves)))
The code above initially generates all moves as before (‘moves’). Then for each move determines which ones (if any) create a winning board for the next-player (‘wins’) and similarly winning options for the last-player (‘blocks’). If there is a win or wins for the next-player, return one. If there is no win but a block or blocks, return one. Otherwise return all available moves as before.
Now the walk code can be re-run using the modified move generation function (highlighted below).
(defn ttt-walk
"Recursively walk the TTT game tree and update results for each node"
[board last-player next-player level dups syms results]
(cond
(contains? @dups board)
(swap! results update-in [level :dup] (fnil inc 0)) ; Duplicate node
(contains? @syms board)
(swap! results update-in [level :sym] (fnil inc 0)) ; Symmetric node
:else
(do
(swap! dups conj board)
(swap! syms clojure.set/union (board-symmetries board))
(if (win-board? board last-player)
(swap! results update-in [level last-player] (fnil inc 0)) ; Win node
(let [moves (gen-moves-forced board last-player next-player)]
(if (empty? moves)
(swap! results update-in [level :draw] (fnil inc 0)) ; Draw node
(do
(swap! results update-in [level :inode] (fnil inc 0)) ; Internal node
(doseq [m moves]
(ttt-walk (assoc board m next-player)
next-player
last-player
(inc level)
dups
syms
results)))))))))
(let [resmap (into (sorted-map) (for [n (range 10)] [n (sorted-map)]))
results (atom resmap)
dups (atom #{})
syms (atom #{})]
(ttt-walk [:e :e :e :e :e :e :e :e :e] :o :x 0 dups syms results)
@results)
;=>
{0 {:inode 1},
1 {:inode 3, :sym 6},
2 {:inode 12, :sym 12},
3 {:dup 3, :inode 38, :sym 43},
4 {:dup 27, :inode 54, :sym 47},
5 {:dup 21, :inode 88, :sym 41},
6 {:dup 28, :inode 83, :sym 28},
7 {:dup 18, :inode 47, :sym 25, :x 25},
8 {:dup 12, :inode 18, :o 11, :sym 11},
9 {:draw 3, :dup 4, :sym 5, :x 6}}
We see a further reduction in the game tree size with the inclusion of forced moves. The game tree is now down to just 389 nodes! The updated tracking table below.
| Node Level |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
Total |
| Upper Bound |
1 |
9 |
72 |
504 |
3,024 |
15,120 |
60,480 |
181,440 |
362,880 |
362,880 |
986,410 |
| Actual after accounting for winning nodes |
| Internal |
1 |
9 |
72 |
504 |
3,024 |
13,680 |
49,392 |
100,224 |
127,872 |
46,080 |
340,858 |
| X-wins |
|
|
|
|
|
1,440 |
|
47,952 |
|
81,792 |
131,184 |
| O-wins |
|
|
|
|
|
|
5,328 |
|
72,576 |
|
77,904 |
| Total |
1 |
9 |
72 |
504 |
3,024 |
15,120 |
54,720 |
148,176 |
200,448 |
127,872 |
549,946 |
| After accounting for duplicate nodes |
| Upper Bound |
1 |
9 |
72 |
252 |
756 |
1,260 |
1,680 |
1,260 |
630 |
126 |
6,046 |
| Actual after accounting for duplicate and winning nodes |
| Internal |
1 |
9 |
72 |
252 |
756 |
1,140 |
1,372 |
696 |
222 |
16 |
4,536 |
| X-wins |
|
|
|
|
|
120 |
|
444 |
|
62 |
626 |
| O-wins |
|
|
|
|
|
|
148 |
|
168 |
|
316 |
| Total |
1 |
9 |
72 |
252 |
756 |
1,260 |
1,520 |
1,140 |
390 |
78 |
5,478 |
| Actual after accounting for symmetric, duplicate and winning nodes |
| Internal |
1 |
3 |
12 |
38 |
108 |
153 |
183 |
95 |
34 |
3 |
630 |
| X-wins |
|
|
|
|
|
21 |
|
58 |
|
12 |
91 |
| O-wins |
|
|
|
|
|
|
21 |
|
23 |
|
44 |
| Total |
1 |
3 |
12 |
38 |
108 |
174 |
204 |
153 |
57 |
15 |
765 |
| Actual after accounting for forced, symmetric, duplicate and winning nodes |
| Internal |
1 |
3 |
12 |
38 |
54 |
88 |
83 |
47 |
18 |
3 |
347 |
| X-wins |
|
|
|
|
|
|
|
25 |
|
6 |
31 |
| O-wins |
|
|
|
|
|
|
|
|
11 |
|
11 |
| Total |
1 |
3 |
12 |
38 |
54 |
88 |
83 |
72 |
29 |
9 |
389 |
There are two noteworthy changes:
- the X-wins at level 5 and O-wins at level 6 have gone
- despite the fact that a player now always blocks an opponent’s winning threat (ie. two-in-a-row) there are still won positions for both the X-player and the O-player
The first point makes sense as the easy wins (through careless defending) no longer occur as the opponent will now always block a two-in-a-row threat.
But what is going on with the second point? Is the code wrong?
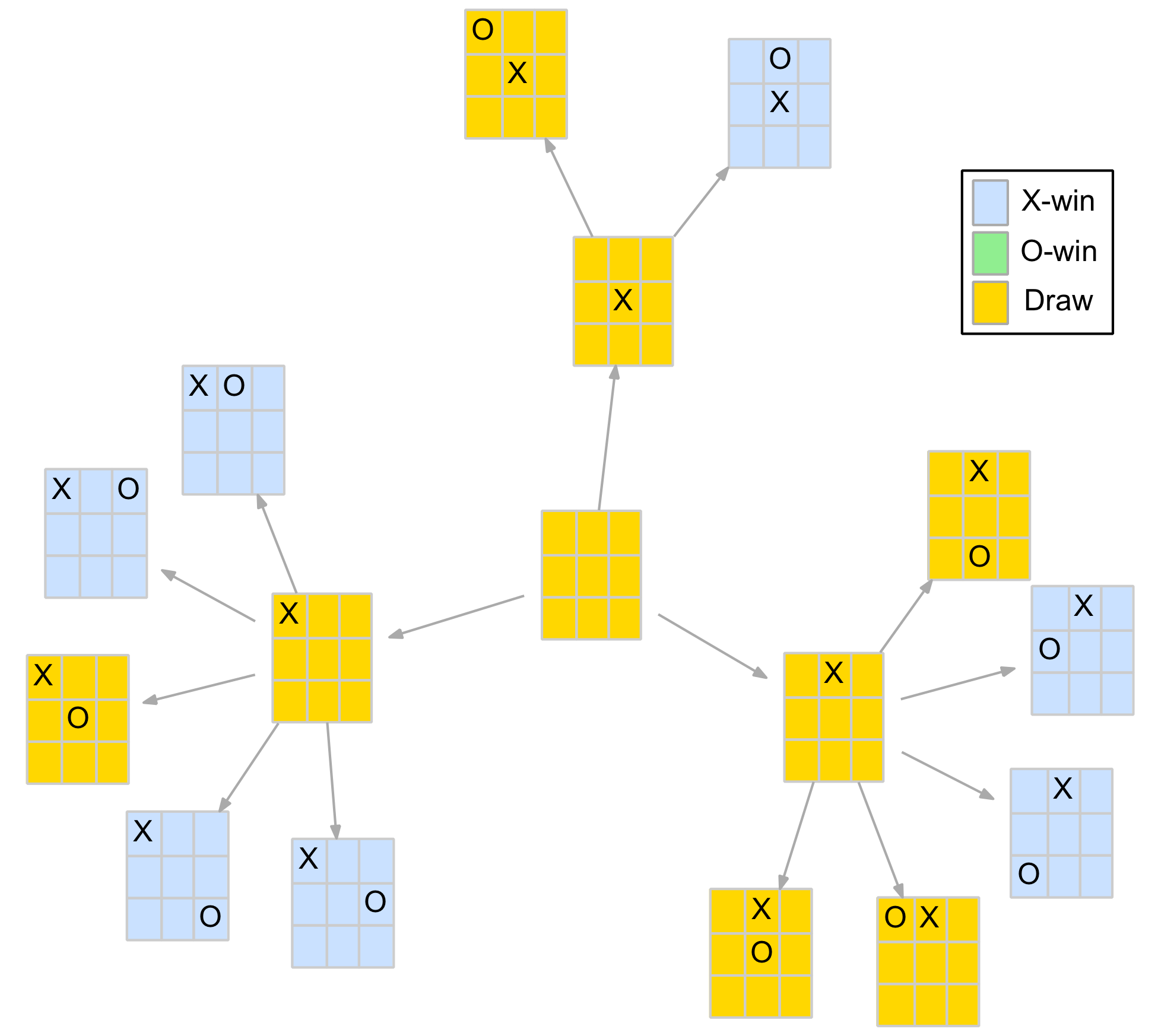
No! In fact, it reveals about the only interesting tactical feature of the game. It is possible to create a position with two winning threats (ie. 2 x two-in-a-row) at the same time. This is called a fork. As the opponent can only block one, a player that can achieve a forked position is guaranteed to win.
Below are some examples of forked positions with the two threats highlighted. The first two show the O-player to move and are winning for the X-player. The last one shows the X-player to move and is winning for the O-player.
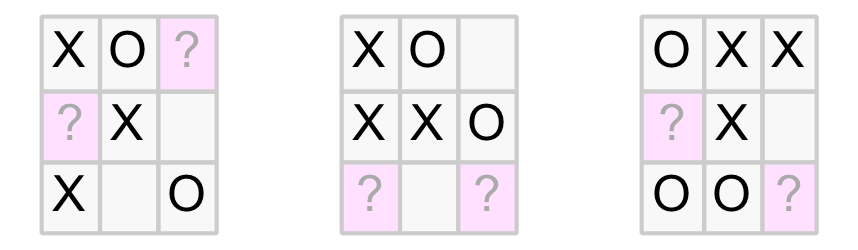
Fork position examples
To understand the number and level of forked positions we need another helper function that tests for these positions. The tree walking code can then be modified to record the forked position details. Remember a forked node is still an internal node, so we would expect the previous :inode count to split between non-forked (:inode) internal nodes and forked (:fork) internal nodes.
The code below shows the helper function, modified walk code (highlighted) and results.
(defn fork-board?
"Return true if it is a winning 'fork' board for the specified player.
That is last-player has two winning moves AND next-player has none"
[board last-p next-p]
(let [moves (filter #(= :e (board %)) (range 9))
next-wins (filter #(win-board? (assoc board % next-p) next-p) moves)
last-wins (filter #(win-board? (assoc board % last-p) last-p) moves)]
(and (= (count last-wins) 2) (zero? (count next-wins)))))
(defn ttt-walk
"Recursively walk the TTT game tree and update results for each node"
[board last-player next-player level dups syms results]
(cond
(contains? @dups board)
(swap! results update-in [level :dup] (fnil inc 0)) ; Duplicate node
(contains? @syms board)
(swap! results update-in [level :sym] (fnil inc 0)) ; Symmetric node
:else
(do
(swap! dups conj board)
(swap! syms clojure.set/union (board-symmetries board))
(if (win-board? board last-player)
(swap! results update-in [level last-player] (fnil inc 0)) ; Win node
(let [moves (gen-moves-forced board last-player next-player)]
(if (empty? moves)
(swap! results update-in [level :draw] (fnil inc 0)) ; Draw node
(do
(if (fork-board? board last-player next-player)
(swap! results update-in [level :fork] (fnil inc 0)) ; Internal fork
(swap! results update-in [level :inode] (fnil inc 0))) ; Internal node
(doseq [m moves]
(ttt-walk (assoc board m next-player)
next-player
last-player
(inc level)
dups
syms
results)))))))))
(let [resmap (into (sorted-map) (for [n (range 10)] [n (sorted-map)]))
results (atom resmap)
dups (atom #{})
syms (atom #{})]
(ttt-walk [:e :e :e :e :e :e :e :e :e] :o :x 0 dups syms results)
@results)
;=>
{0 {:inode 1}
1 {:inode 3, :sym 6}
2 {:inode 12, :sym 12}
3 {:dup 3, :inode 38, :sym 43}
4 {:dup 27, :inode 54, :sym 47}
5 {:dup 21, :fork 36, :inode 52, :sym 41}
6 {:dup 28, :fork 14, :inode 69, :sym 28}
7 {:dup 18, :fork 9, :inode 38, :sym 25, :x 25}
8 {:dup 12, :inode 18, :o 11, :sym 11}
9 {:draw 3, :dup 4, :sym 5, :x 6}}
These results show forked positions start at level 5 (3 x Xs and 2 x Os) which is expected as at least three Xs are required to form a fork. Also the sum of the forked and non-forked nodes equals the previous internal node counts. There is also a reasonably large number of forked positions suggesting that forks are a significant tactical component of the game.
Visualisation
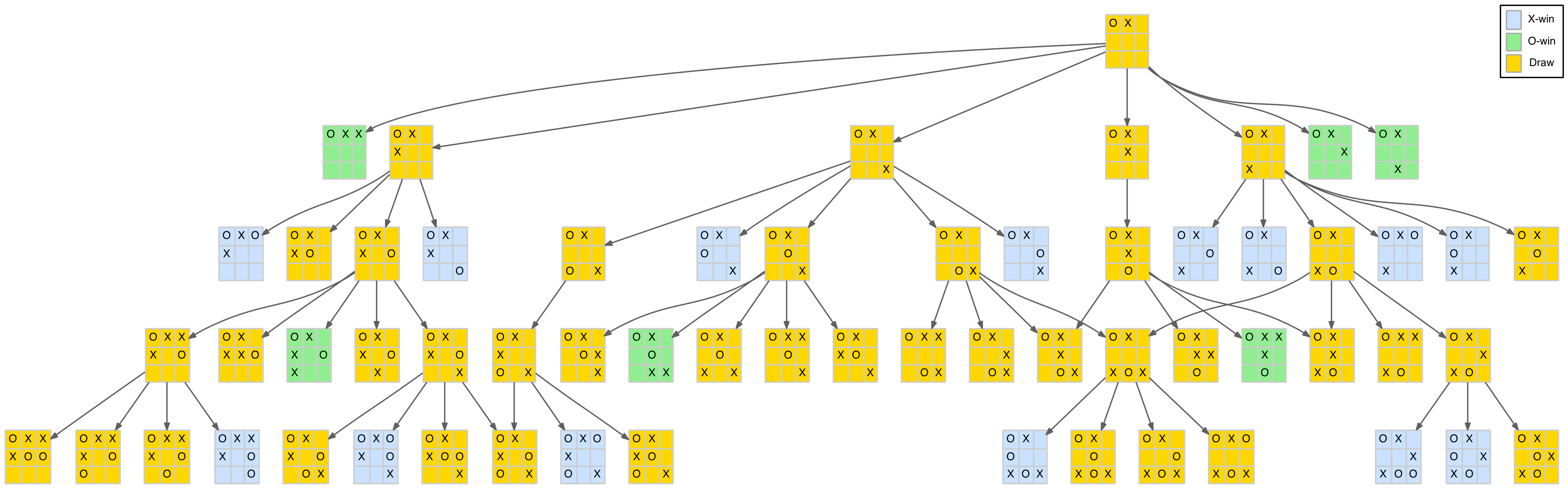
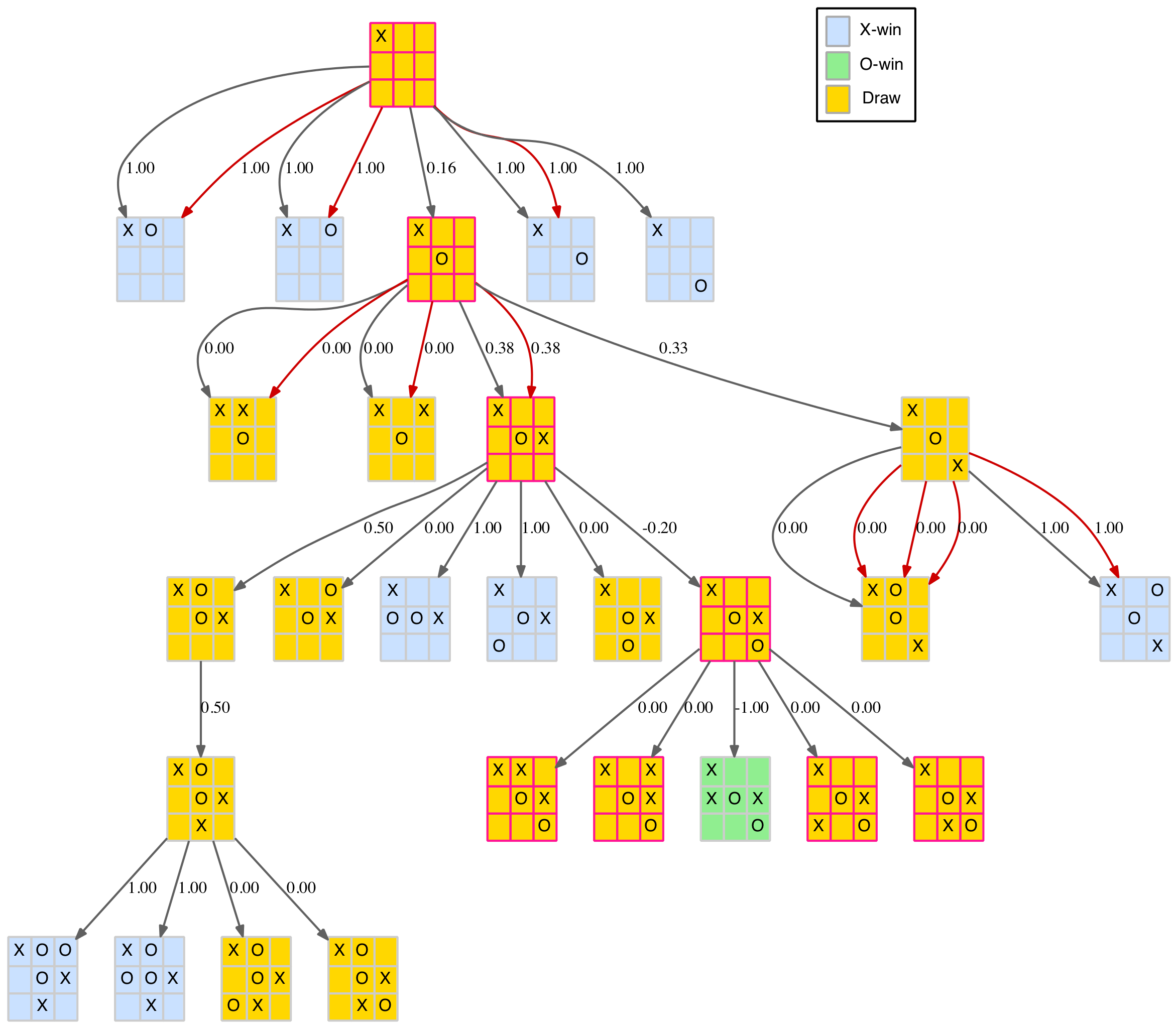
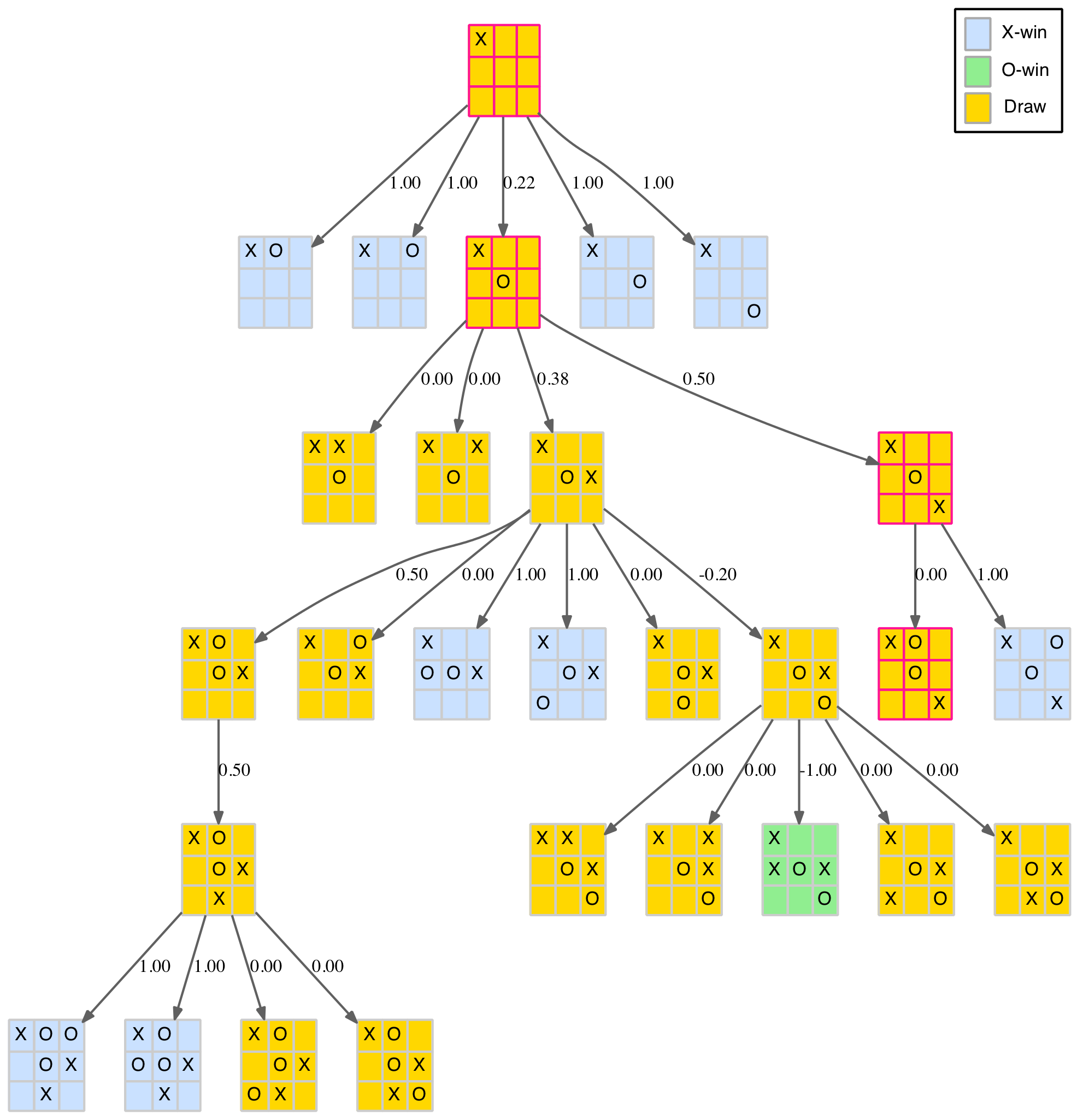
Until now we have mainly dealt with the size and shape of the TTT game tree. However, as we have managed to prune it down to a relatively small number of nodes, it is possible to display it, or part of it, directly. Using the fantastic Graphviz and the convenient Clojure library dorothy that greatly simplifies creating Graphviz configurations from Clojure, it is relatively straightforward to create a visual representation of the game tree.
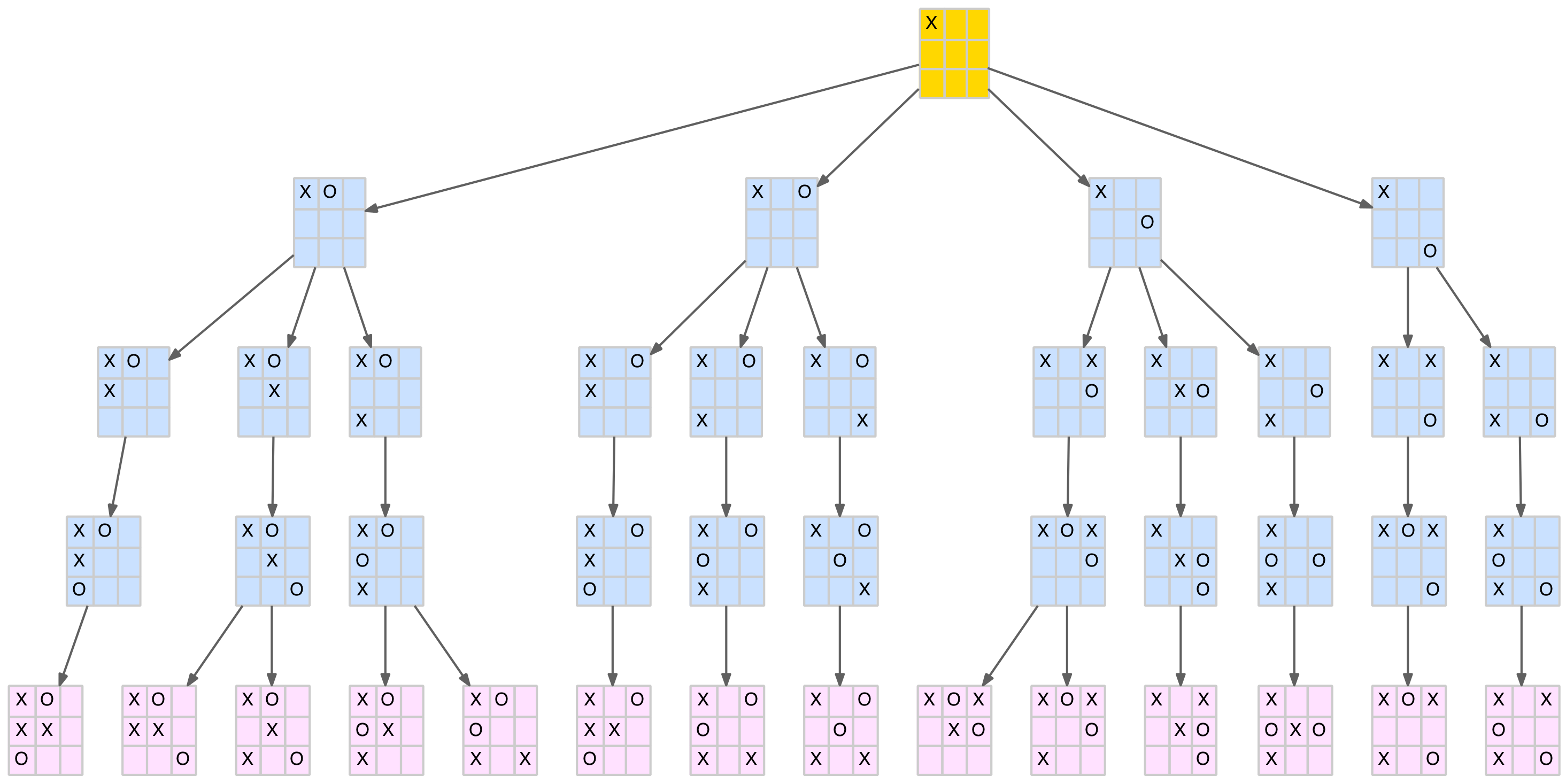
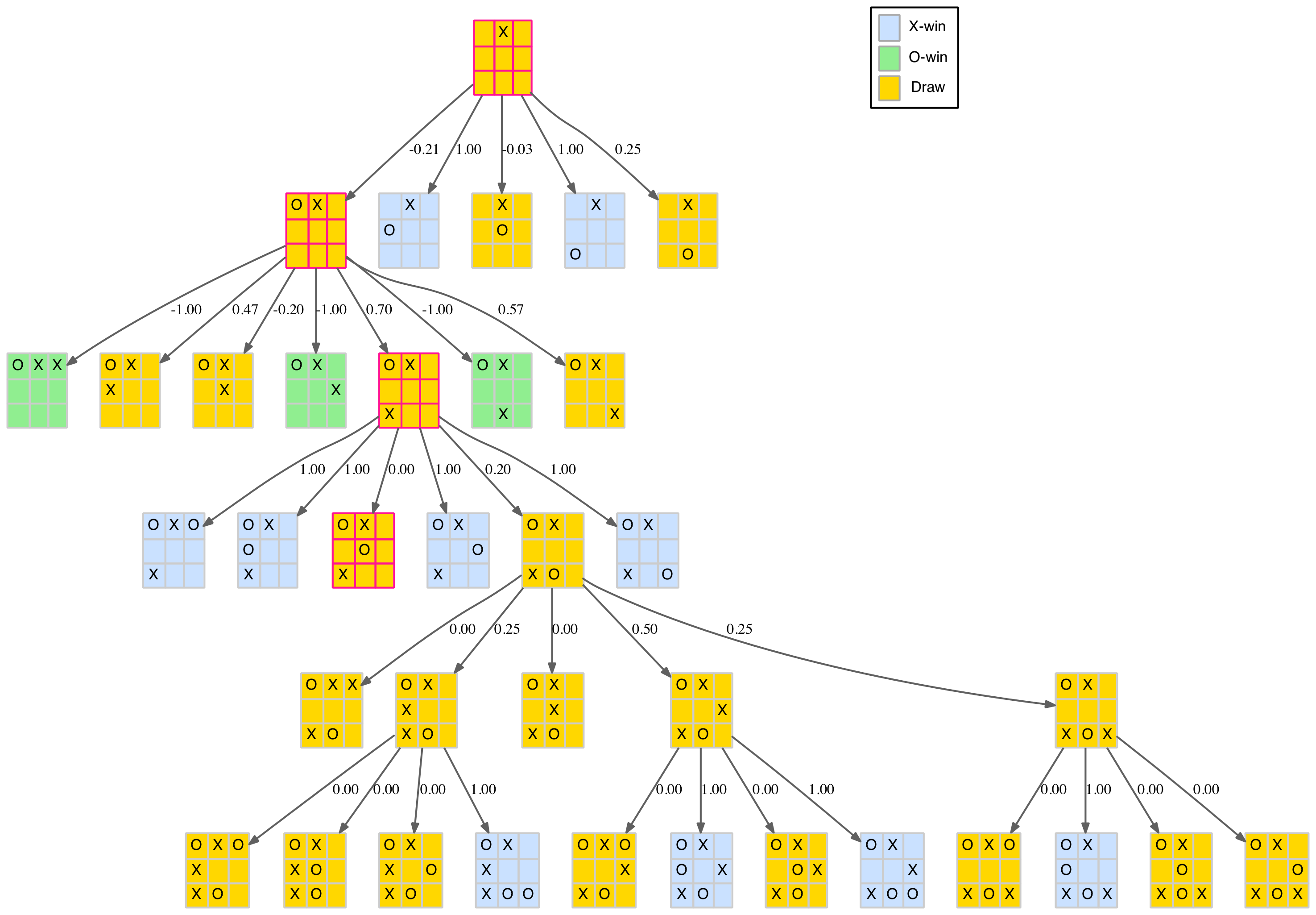
The full tree is still a bit large to comfortably display as one image but for the intrepid a link to the full tree in PDF format is provided at the end of this section, along with PDFs for each of the three first-move branches. The smallest of these branches, first move in the centre of the board, is shown below.
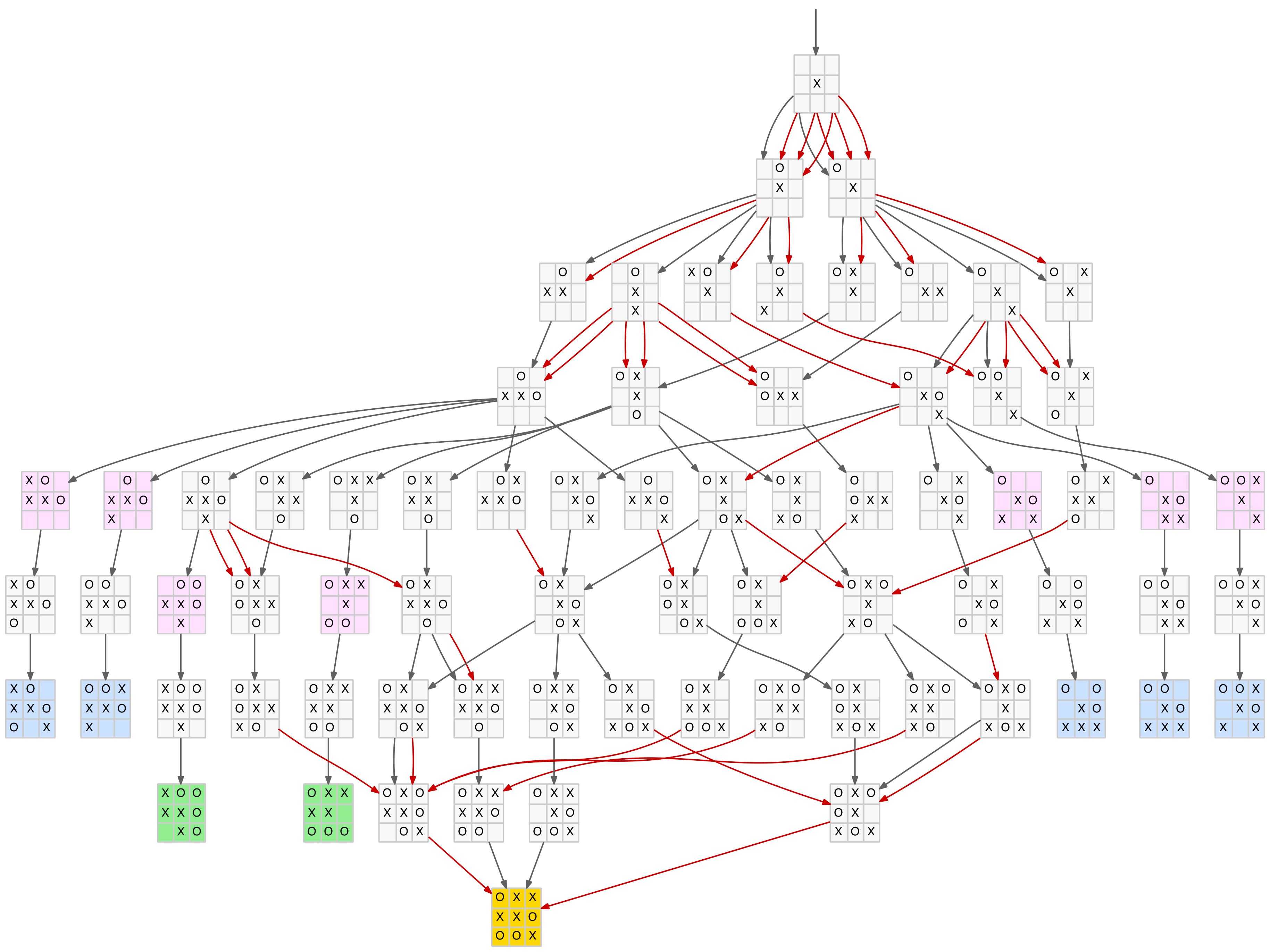
Branch of the full game tree
The nodes are colour-coded as follows:
- Blue – X-win
- Green – O-win
- Gold – draw
- Pink – fork
The dark edges (links between nodes) represent standard parent-child relationships. The red edges show the same parent-child relationships but with a symmetrical transformation included. That is, the child is derived from the parent with a new move added but then rotated or reflected to an existing node. Multiple red edges indicate that several of the parent’s child nodes transformed to the same final child node.
Note there is only one drawn board (the Island pattern – see above) as this pattern is the only one with an X-token in the centre square.
Links to the final game tree diagrams in PDF format:
The code that generates Graphviz for these diagrams is not included here but is relatively easy to derive from the tree walking code above as follows:
- add a new atom to hold the dorothy data structure and pass it like ‘dups’ and ‘syms’
- add a parent node argument that is passed down the recursion chain (for edge generation – see below)
- add a dorothy node vector for each node to the dorothy data structure
- add a dorothy edge vector connecting the node to its parent to the dorothy data structure
- render the resulting dorothy data structure
Conclusion (Part 1)
We have shown that TTT can be represented as a 10-level game tree and that by accounting for duplicates, symmetries and forced moves, this tree can be reduced from over 500,000 nodes down to its essence of just 389 nodes. Despite always correctly blocking an opponents threats there are still won positions within this tree because of the existence of forked positions. These positions provide the main (only) tactical component of the game. Finally we learned that there are only three drawn position patterns.
In part 2 of this blog we will look at player strategies and seek to answer questions like:
- Can either player force a win?
- What is the best move in a given position?
- Can the game tree be reduced further?